Part 8/8: A blog post series by Dong Huynh, Sophie Stalla-Bourdillon and Luc Moreau
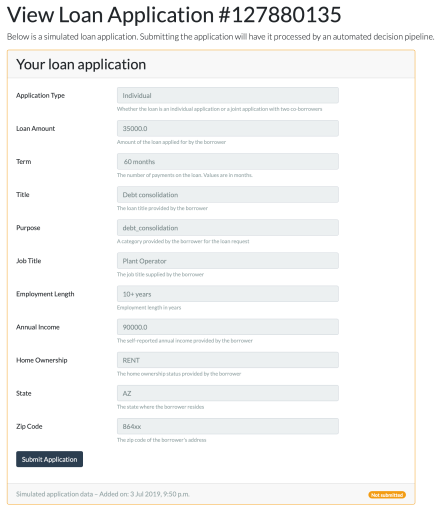
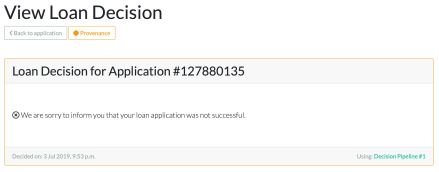
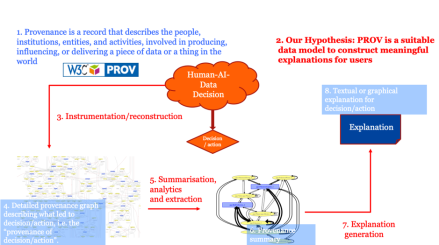
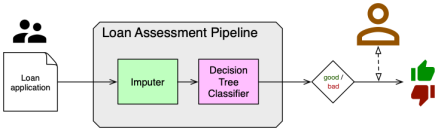
For this EPSRC impact acceleration project conducted over a period of three months, we have implemented the Loan Decision scenario, instrumented the pipeline so that it produces provenance, categorised explanations according to their audience and their purpose, built an explanation-generation prototype, and wrapped the whole system in an online demonstrator.
This work aimed to demonstrate that provenance, defined as a record that describes the people, institutions, entities, and activities involved in producing, influencing, or delivering a decision, is a solid foundation for generating explanations.
We are delighted to release a report summarising all this work.
https://explain.openprovenance.org/report/
Some lessons can be drawn from this piece of work.
1. General considerations
Given the short duration of the project, there are inevitably some limitations. First, we discuss some general considerations.
- First, we designed this prototype for one application scenario, for one machine learning pipeline, for one specific regulatory framework (GDPR), and for a subset of requirements from this framework. It is our intent to generalise the approach to other scenarios, regulations and requirements.
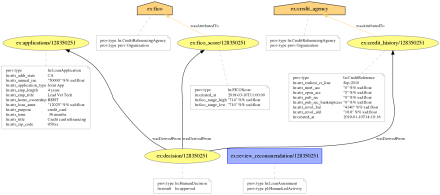
- Second, the approach is predicated on finding specific mark-ups in the provenance, to be able to construct the relevant explanations. Besides the above generalisation, there is also a clear need to document such mark-ups, so that data controllers can adapt their system to produce suitably annotated provenance. It has to be understood by data controllers that a failure to generate provenance with the right mark-ups will result in the system’s inability of constructing some explanations.
- Third, adequate tools need to be provided to assist data controllers in producing the right provenance information, and in checking that it addresses data protection (or others) requirements they are under the obligation to meet.
- Fourth, explanations can and should be refined to fully meet their purposes. Extensive requirement capturing and user studies will help validate these.
- Fifth, it is our belief that explanations could be viewed as more than just one paragraph communicated to the data subject in a single request-response interaction. We envisage explanations potentially as part of a dialogue between the system and its targeted recipients. A mechanism to design such an explanation service would, therefore, be required.
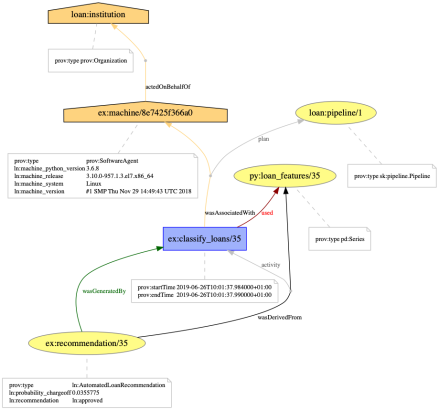
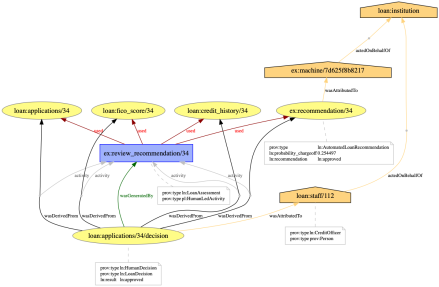
- Finally, some aspects of the decision-making pipeline are currently not explained. It is particularly the case of the machine learning algorithm itself, which remains a black-box: the algorithm was used to create a model, and the model was used to classify some input data. Both the model creation and classification are modelled by activities in the provenance. If some libraries are able to generate further provenance, this, in turn, can be turned into explanations.
2. Refining Explanations
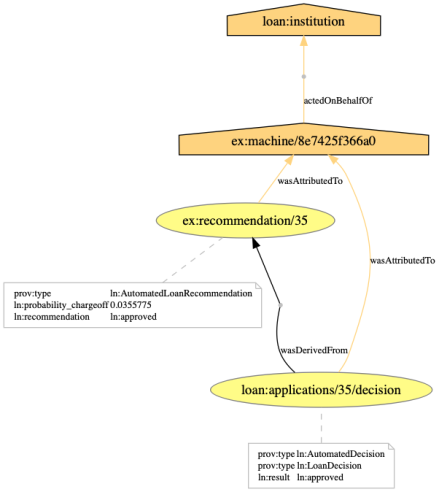
- We generate different explanations for automated and human decisions. Something to investigate is how meaningful the human involvement is. How much is added by the human on top of the automated recommendation they proceed? Can the meaningfulness be determined automatically? Which semantic mark-up in the provenance would help with this task?
- We were able to demonstrate that some loan application characteristics (or elements of third-party data such as credit reference) were not used by the decision-making pipeline. This information, while certainly useful, is looking at “syntactic usage”: some data may have been passed to the pipeline, but may or may not have been effectively used to reach the decision. In other words, the data may or may not have had an influence on the final decision. However, such information can only be surfaced if we gain a better understanding of the black box.
- Counter-factual explanations. We have demonstrated that it is possible to construct simple counter-factual explanations out of provenance. By simply considering alternate loan applications in a counter-factual world (e.g. loan for a different purpose, for a different amount, for a data subject with different profile), and applying the pipeline, we obtain counter-factual decisions. By marking the original loan application and associated decision, as well as alternate applications, we were able to construct an example of counter-factual explanation. This approach needs to be generalised and the nature of explanations that can be supported needs to be further studied.
3. Where next?
This limited proof-of-concept exercise is only the start of a journey. With the new EPSRC-funded PLEAD: Provenance-driven and Legally-grounded Explanations for Automated Decisions, we are about to embark in novel research to address some of above concerns. More posts on this topic will follow.
PLEAD Project: https://plead-project.org/
Full report for this project: https://explain.openprovenance.org/report/
Demonstrator: https://explain.openprovenance.org/