The aim of this blog post is to provide simple guidelines to generate provenance using the PROV-Template approach.
A quick reminder: a provenance template is a PROV document, describing the provenance that it is intended to be generated. A provenance template includes some variables that are placeholders for values. So, a provenance template can be seen as a declarative specification of the provenance intended to be generated by an application. A set of bindings contains associations between variables and values. The PROV-template expansion algorithm, when provided with a template and a set of bindings, generates a provenance document, in which variables have been replaced by values.
Therefore, three steps are involved in this methodology.
- Design a “provenance template” describing the structure of the provenance intended to be generated.
- Instrument the application, log values, and create “binding files” from these values.
- Produce provenance by expanding the template using binding files.
We consider a simple computation, which we would like to describe with provenance. The computation consisted of 3 calls of binary functions: the functions were composed in such a way that the results of two calls were used by the third one. To simplify, we assume that the operations were arithmetic +, -, and *, and the values flowing and out of these operations were integers. Note my use of past tense: the aim of provenance is to describe past computation, as opposed to a future, hypothetical computation (or workflow).
(10+11)-(7*5)
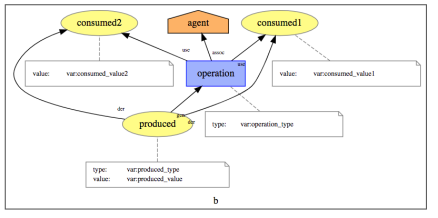
As we have 3 binary functions, we design a template describing the invocation of a binary function. It consists of an activity (denoted by variable operation), two used entities (denoted by variables consumed1 and consumed2), a generated entity (denoted by variable produced), and an agent (denoted by variable agent) responsible for the activity. Graphically, the template can be represented as follows.

Template for the invocation of a binary function
Using the PROV-N notation, the template is expressed as follows. We see that variables are declared in the namespace with prefix var. Each entity and activity is associated with a type, expressed by a variable, which can also be instantiated.
document
prefix tmpl <http://openprovenance.org/tmpl#>
prefix var <http://openprovenance.org/var#>
prefix vargen <http://openprovenance.org/vargen#>
bundle vargen:b
activity(var:operation, [ prov:type='var:operation_type' ] )
agent(var:agent)
wasAssociatedWith(var:operation,var:agent,-)
entity(var:consumed1,[prov:value='var:consumed_value1'])
entity(var:consumed2,[prov:value='var:consumed_value2'])
used(var:operation, var:consumed1, - )
used(var:operation, var:consumed2, - )
entity(var:produced,[prov:type='var:produced_type',prov:value='var:produced_value'])
wasGeneratedBy(var:produced, var:operation, - )
wasDerivedFrom(var:produced, var:consumed1)
wasDerivedFrom(var:produced, var:consumed2)
endBundle
endDocument
To be able to generate provenance, one needs to define so-called “bindings files”, associating variables with values. The structure of bindings file is fairly straightforward: with the most recent version of the ProvToolbox, a bindings file can be expressed as a simple JSON structure. Such JSON structures are very easy to generate programmatically from multiple programming languages. However, in this blog post, we do not want to actually program anything in order to generate provenance.
Therefore, we are going to assume that the application already logs values of interest. We are further going to assume that the data can be easily converted to a tabular format, and specifically, that a CSV (comma separated values) representation can be constructed from those logs. The structure that we expect is illustrated in the following figure. In the first line of the file, we find variable names (exactly those found in the template) acting as column headers. In the second line, we find the type of the values found in the table.

Application log as a CSV file. First line contains variable names whereas second line contains the type of their values. Subsequent lines are the actual values.
Concretely, the CSV file uses commas as separator. The third, fourth, and five lines contain deftail of the invocations of the plus, times, and subtraction functions.
operation, operation_type, consumed1, consumed_value1, consumed2, consumed_value2, produced, produced_value, agent
prov:QUALIFIED_NAME, prov:QUALIFIED_NAME, prov:QUALIFIED_NAME, xsd:int, prov:QUALIFIED_NAME, xsd:int, prov:QUALIFIED_NAME, xsd:int, prov:QUALIFIED_NAME
ex:op1, ex:plus, ex:e1, 10, ex:e2, 11, ex:e3, 21, ex:Luc
ex:op2, ex:times, ex:e4, 5, ex:e5, 7, ex:e6, 35, ex:Luc
ex:op3, ex:subtraction, ex:e3, 21, ex:e6, 35, ex:e7, -14, ex:Luc
Each line can automatically be converted to a JSON file. For instance, the third line containing the details of the addition operation can be converted to the following JSON structure, which is essentially a dictionary associating each variable with its corresponding value, with an explicit representation of the typing information where appropriate.
{
"var":
{"operation": [{"@id": "ex:op1"}],
"operation_type": [{"@id": "ex:plus"}],
"consumed1": [{"@id": "ex:e1"}],
"consumed_value1": [ {"@value": "10", "@type": "xsd:int"}],
"consumed2": [{"@id": "ex:e2"}],
"consumed_value2": [{"@value": "11", "@type": "xsd:int"}],
"produced": [{"@id": "ex:e3"}],
"produced_value": [ {"@value": "21", "@type": "xsd:int"} ],
"agent": [{"@id": "ex:Luc"}]},
"context": {"ex": "http://example.org/"}
}
We do not need to create this JSON structure ourselves. Instead, we provide an awk script that converts a given line into a bindings file.
function ltrim(s) { sub(/^[ \t\r\n]+/, "", s); return s }
function rtrim(s) { sub(/[ \t\r\n]+$/, "", s); return s }
function trim(s) { return rtrim(ltrim(s)); }
BEGIN {
printf("{\"var\":\n{")
OFS=FS=","
}
NR==1 { # Process header
for (i=1;i<=NF;i++)
head[i] = trim($i)
next
}
NR==2 { # Process types
for (i=1;i<=NF;i++)
type[i] = trim($i)
next
}
NR==line{
first=1
for (i=1;i<=NF;i++) { # For each field
if (first) {
first=0
} else {
printf ","
}
if (type[i]=="prov:QUALIFIED_NAME") {
printf "\"%s\": [{\"@id\": \"%s\"}]", trim(head[i]), trim($i)
} else if (type[i]=="xsd:string") {
printf "\"%s\": [ \"%s\" ]", trim(head[i]), trim($i)
} else {
printf "\"%s\": [ {\"@value\": \"%s\", \"@type\": \"%s\"} ]",trim(head[i]), trim($i), trim(type[i])
}
}
printf "\n"
}
END {
printf("},\n")
printf("\"context\": {\"ex\": \"http://example.org/\"}\n")
printf("}\n")
}
To facilitate the processing, we even provide a Makefile with a target do.csv that processes a line (variable LINE) of the csv file to generate a bindings file. It is then used by the utility provconvert to expand the template file. The target workflow hard-codes the presence of three lines in the CSV, the generation of a bindings file for each line, and the expansion of the template with these bindings. All files are then merged in a single provenance file using the -merge option of provconvert.
LINE=4
do.csv:
cat bindings.csv | awk -v line=$(LINE) -f src/main/resources/awk/tobindings.awk > target/bindings$(LINE).json
provconvert -bindver 3 -infile template_block.provn -bindings target/bindings$(LINE).json -outfile target/block$(LINE).provn
workflow:
$(MAKE) LINE=3 do.csv
$(MAKE) LINE=4 do.csv
$(MAKE) LINE=5 do.csv
printf "file, target/block3.provn, provn\nfile, target/block4.provn, provn\nfile, target/block5.provn, provn\n" | provconvert -merge - -flatten -outfile target/wfl.svg
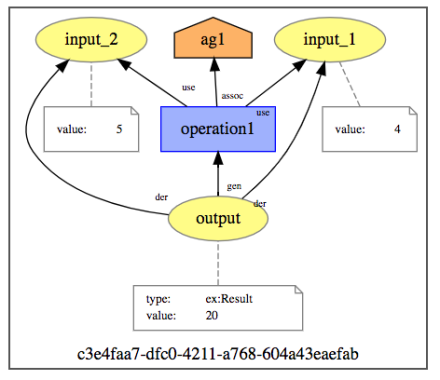
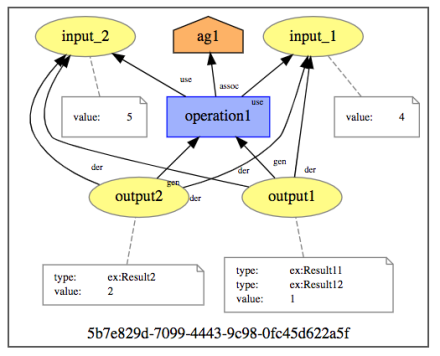
The resulting provenance is displayed in the following figure.

Expanded provenance showing three activities, consumed and generated entities, and an agent.
Concluding Remarks
Given a log file in CSV format, we have shown it is becoming easy to generate PROV-compliant provenance without having to write a single line of code: an awk script converts CSV data to JSON, used to expand a template expressed in a PROV-compliant format.
For the provenance to be meaningful, the application must be instrumented to log the relevant values. For instance, each entity/agent/activity is expected to have been given a unique identifier.
The template design phase is also critical. In our design, we decided that one template would describe the invocation of a single function. The same template was reused for all function calls. Alternatives are possible: multiple activities could be described in a single template, alternatively different types of activities could be described in different templates. I will come back to this issue in another blog post in a few weeks.